
This post demonstrates techniques to find unique and duplicate values in a SAS data set. It is one of the most common interview questions as it is commonly used in day-to-day data management activities. SAS has some easy inbuilt options to handle duplicate records.
Below is a sample data set that can be used for demonstration.
SAMPLE DATA SET
| ID | Name | Score |
|---|---|---|
| 1 | David | 45 |
| 1 | David | 74 |
| 2 | Sam | 45 |
| 2 | Ram | 54 |
| 3 | Bane | 87 |
| 3 | Mary | 92 |
| 3 | Bane | 87 |
| 4 | Dane | 23 |
| 5 | Jenny | 87 |
| 5 | Ken | 87 |
| 6 | Simran | 63 |
| 8 | Priya | 72 |
Create this data set in SAS
data readin; input ID Name $ Score; cards; 1 David 45 1 David 74 2 Sam 45 2 Ram 54 3 Bane 87 3 Mary 92 3 Bane 87 4 Dane 23 5 Jenny 87 5 Ken 87 6 Simran 63 8 Priya 72 ; run;
In PROC SORT, there are two options by which we can remove duplicates.
The NODUPKEY option removes duplicate observations where value of a variable listed in BY statement is repeated while NODUP option removes duplicate observations where values in all the variables are repeated (identical observations).
The difference between these two options are explained in detail below with SAS codes-
| PROC SORT DATA = readin NODUPKEY; BY ID; RUN; | PROC SORT DATA = readin NODUP; BY ID; RUN; |
The output is shown below :
| NODUPKEY | NODUP | ||||
| ID | Name | Score | ID | Name | Score |
| 1 | David | 45 | 1 | David | 45 |
| 2 | Sam | 45 | 1 | David | 74 |
| 3 | Bane | 87 | 2 | Sam | 45 |
| 4 | Dane | 23 | 2 | Ram | 54 |
| 5 | Jenny | 87 | 3 | Bane | 87 |
| 6 | Simran | 63 | 3 | Mary | 92 |
| 8 | Priya | 72 | 3 | Bane | 87 |
| 4 | Dane | 23 | |||
| 5 | Jenny | 87 | |||
| 5 | Ken | 87 | |||
| 6 | Simran | 63 | |||
| 8 | Priya | 72 | |||
The NODUPKEY has deleted 5 observations with duplicate values whereas NODUP has not deleted any observations.
Why no value has been deleted when NODUP option is used?Although ID 3 has two identical records (See observation 5 and 7), NODUP option has not removed them. It is because they are not next to one another in the dataset and SAS only looks at one record back.
To fix this issue, sort on all the variables in the dataset READIN.
To sort by all the variables without having to list them all in the program, you can use the keyword ‘_ALL_’ in the BY statement (see below).
PROC SORT DATA = readin NODUP; BY _all_; RUN;
The output is shown below :
|
| SAS NODUP Option |
STORING DUPLICATES
Use the DUPOUT= option with NODUPKEY (or NODUP) to output duplicates to the specified SAS data set:
PROC SORT DATA = readin NODUPKEY DUPOUT= readin1; BY ID; RUN;
The output is shown below :
 |
| Output Dataset |
FIRST.VARIABLE assigns the value of 1 for the first observation in a BY group and the value of 0 for all other observations in the BY group.
LAST.VARIABLE assigns the value of 1 for the last observation in a BY group and the value of 0 for all other observations in the BY group.
Data set must be in sort order.
Use PROC SORT to sort the data set by ID.
PROC SORT DATA = READIN; BY ID; RUN; DATA READIN1; SET READIN; BY ID; First_ID= First.ID; Last_ID= Last.ID; RUN;
Note : FIRST./LAST. variables are temporary variables. That means they are not visible in the newly created data set. To make them visible, we need to create two new variables. In the program above, i have created First_ID and Last_ID variables.
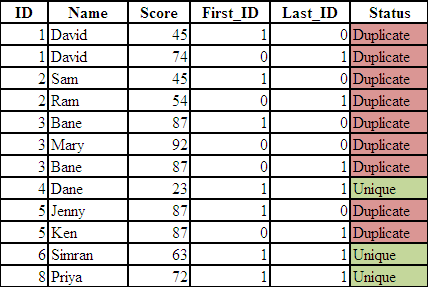 |
| Unique and Duplicate Flag |
DATA DUPLICATES UNIQUE; SET READIN; BY ID; First_ID= First.ID; Last_ID= Last.ID; IF NOT (First_ID = 1 and Last_ID = 1) THEN OUTPUT DUPLICATES; ELSE OUTPUT UNIQUE; RUN;Explanation

About Author:
Deepanshu founded ListenData with a simple objective - Make analytics easy to understand and follow. He has over 10 years of experience in data science. During his tenure, he worked with global clients in various domains like Banking, Insurance, Private Equity, Telecom and HR.
While I love having friends who agree, I only learn from those who don't
Let's Get Connected Email LinkedIn
All the questions and Answers are really informative and useful. I heart fully appreciate your effort.Please keep on post latest questions and Answers. They help us a lot. Reply Delete